

Share this content
Wer schon einmal mit einem Computerausfall und dem Verlust von Daten zu kämpfen hatte, weiß, wie wichtig Datensicherheit und Redundanzen vor allem bei einer unternehmenskritischen Software wie einem ERP-System sind. Hier beanwortet Julian Bischof, IT-Administrator der metas GmbH und Experte für metas fresh Installation und Datenbankadministration, über seine Erfahrungen und Meinungen zum Thema Cluster und warum er nachts ruhig schlafen kann.
Was bedeutet „Clustering“?
Julian Bischof: Ein Hochverfügbarkeitscluster ist ein Verbund aus mehreren, miteinander vernetzten Computern, die so konfiguriert sind, dass die Aufgaben eines ausgefallenen Computers von einem anderen System übernommen werden können.
Wo liegt der Unterschied zu normalen täglichen Backups?
Julian Bischof: Im Unterschied zu einem täglichen Datenbank-Backup, werden Änderungen an der Datenbank, je nach Netzwerkanbindung der Cluster-Knoten, in unter einer Sekunde miteinander synchronisiert. Bei einem täglichen Backup werden nur Änderungen der vergan-genen 24 Stunden gesichert. Mit dieser kostengünstigen Methode kann allerdings im Falle eines Serverausfalls die Arbeit eines gesamten Tages verloren gehen, inklusive dem Zeitaufwand, einen Ersatz-Server zur Verfügung zu stellen, einzurichten und das Datenbank-Backup wieder einzuspielen. Bei einem Hochverfügbarkeitscluster liegt der Datenverlust im Millisekunden Bereich und da alle Systeme im Idealfall identisch eingerichtet sind, ist das Produktivsystem in Minutenschnelle wieder einsatzbereit.
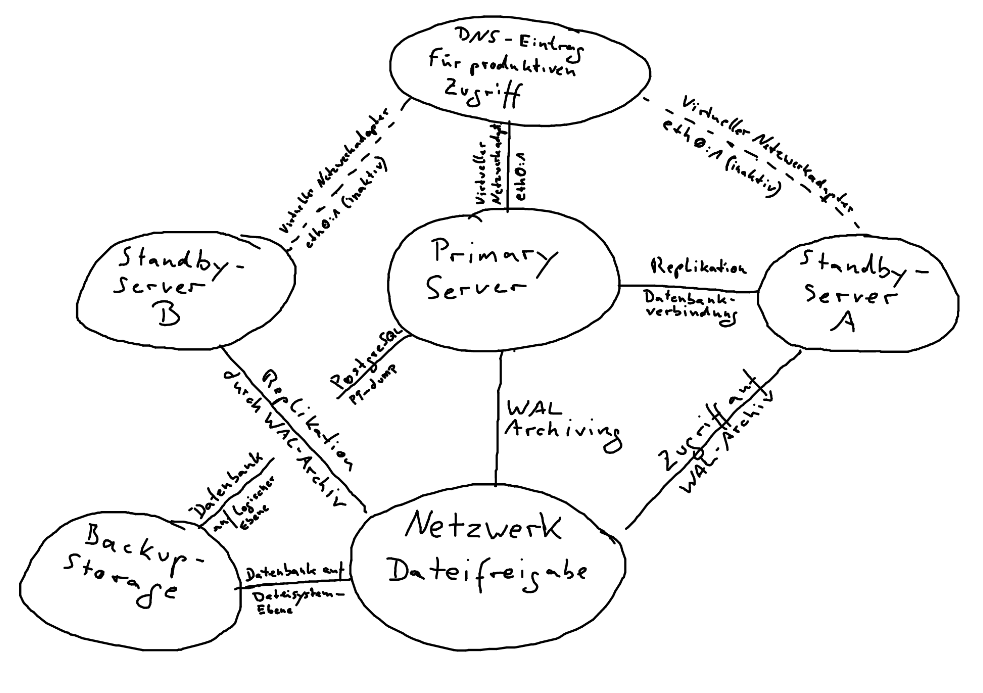
In dem von uns eingesetzten Verfahren, benutzen wir sowohl eine Kombination aus täglicher Sicherung des Applikations-Servers, als auch die vom Postgres-Datenbanksever nativ angebotene Methode des “Streaming-Replication” mit “WAL-Archiving“. Beim “Streaming-Replication” wird eine Netzwerk-Verbindung zwischen dem Hauptserver und dem sogenannten Standby-Server hergestellt. Dabei werden alle Änderungen an der Datenbank in Echtzeit an den Standby-Server übertragen, so dass dieser stets die aktuelle Spiegelung des Hauptsystems darstellt. Durch den Einsatz von “WAL-Archiving” werden diese Änderungen zusätzlich in regelmäßigen Intervallen als Dateien in eine Netzwerkfreigabe geschrieben, wodurch der Standby-Server nach kurzzeitigem Ausfall der Netzwerkverbindung, die Datenbank wieder auf den aktuellen Stand bringen kann. Außerdem ist es mit dieser Methode möglich, die Datenbank auf einen Punkt in der Vergangenheit zurückzuspielen (Point-In-Time Recovery) und dadurch möglicherweise schwerwiegende Änderungen der Datenbank “zurückzudrehen”.
Wie läuft ein Failover ab?
Julian Bischof: Wenn das Produktivsystem ausfallen sollte, kann durch Eingabe von Befehlen auf der Kommandozeile des Standby-Servers, dieser zum primären Produktiv-Server befördert werden. Der Datenbank-Server wird mit schon voreingerichteten Konfigurationsdateien aktiviert und stellt die Datenbank nicht nur für den Produktiv-Betrieb, sondern auch für alle anderen verbundenen Standby-Server. Sollte das ursprüngliche Produktivsystem wieder einsatzfähig sein, kann dieses wieder in den Cluster reintegriert werden und als neuer Standby-Server zur Verfügung stehen.
Warum wird der Failover manuell in die Wege geleitet?
Julian Bischof: Es ist durchaus möglich, die Server so einzurichten, dass diese per “heartbeat” prüfen, ob der jeweilige Cluster-Node noch erreichbar ist, um dann einen automatischen Failover einzuleiten. Dies kann aber sehr unerwünschte und fatale Nebeneffekte mit sich führen, wie zum Beispiel zu einem sogenannten “Split Brain” Zustand, dessen Fehlerbehebung oft mit sehr großem manuellem Aufwand verbunden ist, wobei selbst dann kein Datenverlust garantiert werden kann, ohne auf ein vorheriges Backup zurückgreifen zu müssen.
Wie lange können die Nodes asynchron laufen?
Julian Bischof: Sollte es zu einer Unterbrechung der Netzwerkverbindung der Server kommen und somit keine WAL-Dateien mehr auf den Netzwerkspeicher für die Standby-Server hinterlegt werden können, speichert der Produktiv-Server diese Dateien in einen lokalen Ordner. Dieser Vorgang geschieht so lange, bis entweder der lokale Ordner keinen freien Speicherplatz mehr hat, oder bis der Netzwerkspeicher wieder verfügbar ist, woraufhin der Produktiv-Server diese Dateien von seinem lokalen Verzeichnis in den Netzwerkspeicher verschiebt. Die Standby-Server lesen anschließend die im Netzwerkspeicher gelagerten Dateien ein, bis diese wieder auf dem aktuellen Stand des Produktiv-Servers sind und die Datenübertragung wie gehabt über eine direkte Datenverbindung stattfinden kann.
Was geschieht bei asynchronen Cluster-Nodes?
Julian Bischof: Sollten die Standby-Server dennoch asynchron laufen, was man anhand der Log-Einträge der Datenbank-Server prüfen kann, müssen die Standby-Server wieder reinitialisiert werden. Hier wird vom Produktiv-Server ein neues sogenanntes “Base-Backup” auf Dateisystem-Ebene erstellt, auf die asynchronen Standby-Server eingespielt, wobei diese anschließend mit den aktuellen WAL-Archiven auf den aktuellen Stand gebracht werden.
Share this content