

Share this content
Those who have experienced system failures and the loss of data know exactly how important data security and redundancy is, especially for business-critical software such as an ERP system. Julian Bischof, IT administrator at metas GmbH and expert for metasfresh installation and database administration shares his experiences and views on clustering and why he can get a good night’s sleep.
What does clustering mean?
Julian Bischof: A high-availability cluster is a group of hosts comprising several networked computers that are configured to transfer the tasks of a computer to another system in the event of a failure.
How is this different from making regular daily backups?
Julian Bischof: Unlike a daily database backup, changes in the database, depending on the network connection to the cluster nodes, are synchronized with each other in less than a second. A daily backup only secures changes made during the past 24 hours. With this cost-saving method, however, the work of an entire day can be lost in the event of a server failure, taking into account the time required for organizing and setting up a spare server and reimporting the database backup. In a high-availability cluster, data loss is in the millisecond range and, as all systems ideally have an identical set-up, the production system is once again ready for use within minutes.
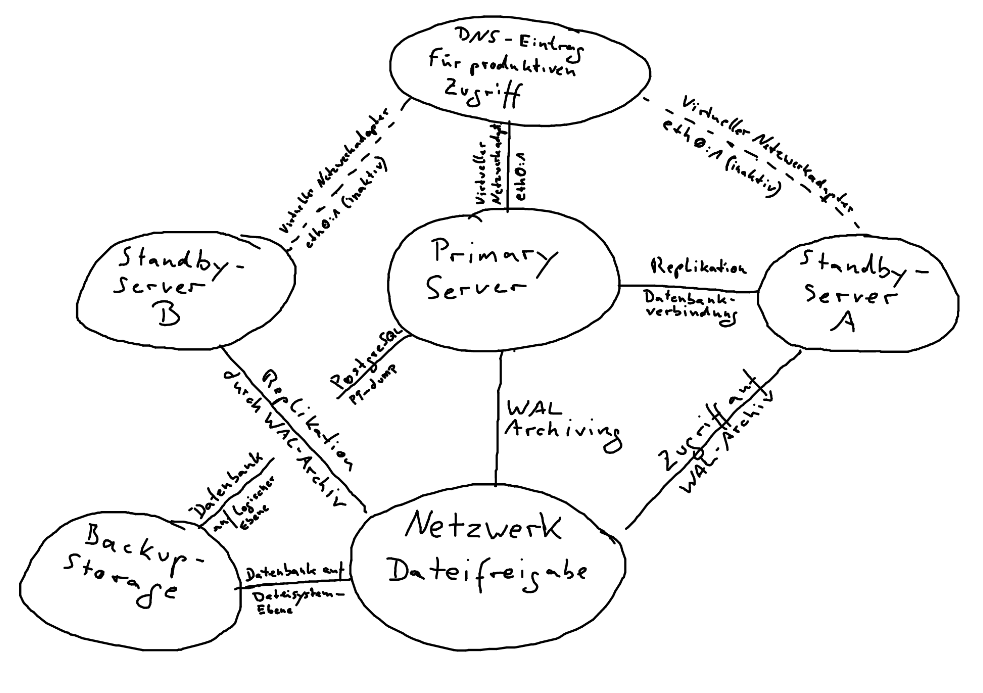
In the process implemented by us, we use both a combination of daily backups of the application server and the native streaming replication method with WAL archiving used by the Postgres database server. The streaming replication process establishes a network connection between the main server and the so-called standby server. In this process, all database changes are transmitted in real time to the standby server which thereby always has the latest replication of the main system. In the WAL archiving process, these changes are additionally copied as files to a network share at regular intervals, whereby the standby server, after a brief failure of the network connection, can restore the database to its current status. Using this method, it is also possible to restore the database to a point in time in the past (point-in-time recovery) and thereby “turn back the clock” in order to neutralize severe changes in the database.
What happens during a failover?
Julian Bischof: In the event of a failure of the production system, the standby server can be promoted to take over the tasks of the primary production server by entering the relevant commands in the command line of the standby server. The database server is activated by means of default configuration files and makes the database available both for production operations and for all other standby servers connected to the system. Once the original production system is operational, it can be reintegrated into the cluster as a new standby server.
Why is the failover initiated manually?
Julian Bischof: It is quite possible to set up the servers such that they can verify using a heartbeat mechanism whether the relevant cluster node is accessible, so as to subsequently initiate an automatic failover if required. This method, however, can have extremely undesirable and even fatal consequences, such as the so-called “split-brain” condition. Remedying this situation often involves enormous manual effort and, despite the effort, cannot always prevent data loss without resorting to a previous backup.
For how long can the nodes run in asynchronous mode?
Julian Bischof: In the event of an interruption in the network connection between the servers and if, as a result, no WAL files can be saved in the network-attached storage for the standby servers, the production server saves these files in a local folder. This process continues until either the local folder has no more free space or until the network storage is available again, whereupon the production server moves these files from its local directory into the network storage. The standby servers then load the files from the network storage until they have attained the updated status of the production server and data transmission can resume via a direct data link.
What happens in the case of asynchronous cluster nodes?
Julian Bischof: If the standby servers continue to run asynchronously – this can be checked on the basis of the log entries of the database server – then they need to be reinitialized. In this context, the production server creates a new so-called “base backup” at file system level and loads it onto the asynchronous standby servers which are then updated with the current WAL archives.
Share this content